
이 글은 '면접을 위한 CS 전공지식 노트' 책을 토대로 작성하였습니다.
메모리 계층
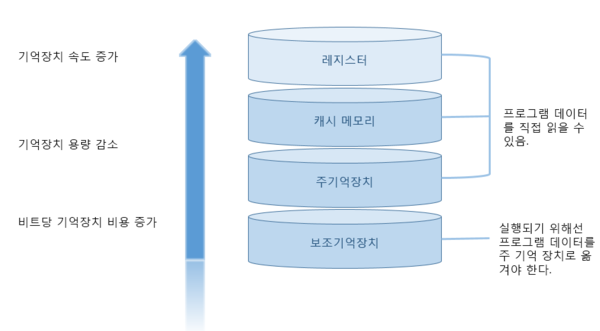
레지스터
CPU 안에 있는 작은 메모리, 휘발성, 속도 가장 빠름, 기억 용량 가장 적음
캐시
L1, L2 캐시를 지칭. 휘발성, 속도 빠름, 기억 용량 적음
주기억장치
RAM을 지칭. 휘발성, 속도 보통, 기억 용량 보통
보조 기억장치
HDD, SSD를 지칭. 비휘발성, 속도 낮음, 기억 용량 많음
계층 위로 올라갈수록 가격은 비싸지고 용량은 작아지고 속도가 빨라지는 특징이 있다. 이러한 계층이 있는 이유는 경제성과 캐시 때문이다. 예를들어 16GB RAM은 8만원이지만 동일 용량의 SSD는 훨씬 더 싸다. CPU에서 멀어질수록 용량은 크고 속도는 느리고 가격은 저렴해지지만 CPU까지 가져오기 위해 추가작업이 필요해지는데 계층과 계층 사이에서 자주사용하는 데이터를 복사해 가까이 둔다.
캐시
데이터를 미리 복사해 놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리
이를 통해 데이터를 접근하는 시간이 오래 걸리는 경우를 해결하고 같은 요청을 처리하는 계산시간을 절약할 수 있다.
실제로 메모리와 CPU의 연산속도 차이가 너무 크기 때문에 그 중간에 레지스터 계층을 둬 속도 차이를 해결한다.
속도 차이를 위해 계층과 계층 사이의 계층을 캐싱 계층이라고 하고, 캐시 메모리와 보조 기억장치 사이에 있는 주기억장치(RAM)을 보조기억장치의 캐싱 계층이라 할 수 있다.
캐시의 지역성
캐시 계층을 두는 것 말고 캐시를 직접 설정할 때는 자주 사용하는 데이터를 기반으로 설정해야 한다.
자주 사용하는 데이터는 시간 지역성과 공간 지역성으로 나뉜다.
public staic void main(String[] args){
int[] arr = new int[10];
for(int i=0;i<arr.length;i++){
arr[i] = i;
}
}시간 지역성
최근 사용한 데이터에 다시 접근하려는 특성. 위의 코드에선 for문의 변수 i에 계속해서 접근해서 사용
공간 지역성
최근 접근한 데이터를 이루고 있는 공간이나 가까운 공간에 접근하는 특성. 위의 코드에선 공간을 나타내는 배열 arr의 각 요소들에 i가 할당되며 해당 배열에 연속적으로 접근
캐시히트와 캐시미스

캐시에서 원하는 데이터를 찾았다면 캐시히트, 해당 데이터가 캐시에 없어 메모리로 가서 데이터를 찾아오는 것을 캐시미스라고 한다.
캐시히트를 하게 되면 해당 데이터를 제어장치를 거쳐 가져오게 되기 때문에 위치도 가깝고, CPU 내부 버스 기반이기에 빠르다.
캐시미스시에는 메모리에서 가져오게 되는데 시스템 버스 기반이기에 느리다.
캐시매핑
캐시히트를 위해 매핑하는 방법
CPU의 레지스터와 RAM 간에 데이터를 주고 받을 때를 기반
레지스터는 주 메모리에 비하면 괴장히 작고 RAM은 굉장히 크기 때문에 작은 레지스터가 캐시 계층 역할을 위해선 매핑이 중요
| 매핑 종류 | 설명 |
| 직접 매핑 | 메모리가 1~100, 캐시가 1~10이면 1:1 ~ 10, 2:1~20... 같이 매핑 처리가 빠르지만 충돌발생이 잦음 |
| 연관 매핑 | 순서를 일치시키지 않고 관련 있는 캐시와 메모리를 매핑 충돌이 적지만 모든 블록을 탐색해야하기에 속도가 느림 |
| 집합 연관 매핑 | 직접 매핑 + 연관 매핑으로 순서는 일치시키지만 집합을 둬서 저장하며 블록화 되어 있어 검색이 효율적 메모리가 1~100, 캐시가 1~10이면 캐시 1~5에는 1~50의 데이터를 무작위로 저장하는 방식 |
캐시를 직접 설정시엔 시간지역성, 공간지역성을 고려하고 상황에 맞는 캐시매핑 방법을 골라 캐시히트를 높이도록 짜야한다.
데이터베이스의 캐싱 계층

데이터베이스 시스템을 구축할 때도 메인 데이터베이스 위에 레디스 데이터 베이스 계층을 캐싱계층으로 둬서 성능을 향상시킴