
사실 JPA 고수 아닙니다.

자바 백엔드 시작을 김영한님의 강의를 보고 시작한만큼 DB접근 기술을 JPA밖에 몰랐었고, 올해 초에 프로그래머스에서 진행한 단순 CRUD 구현을 그만 ! 스터디를 들으면서 JDBC Template를 써보긴했지만 스터디 커리큘럼을 따라가면서도 테이블 정의하는 것과 PrepareStatment로 쿼리짜는 게 귀찮아 DBA의 튜닝 쿼리를 빠르게 적용할 수 있겠다는 장점만 기억하는 것과 JPA를 쓰고 싶다는 생각만 했었던 것 같습니다.
JPA를 한번 더 추상화한 스프링 데이터 JPA를 사용하면서 얼마나 많은 부분이 추상화된지 이론적으로 공부는 했지만 마이바티스를 다뤄보면서 직접 테이블 생성과 쿼리를 짜며 프로젝트를 진행하며 사용한 후기를 정리합니다.
Mybatis-Spring
순수 마이바티스와 스프링과 연동되는 마이바티스 스프링은 전체적으로 빌더로 관리하던 것을 빈으로 관리하면서 Thread - Safe해지는 것과 이름이 살짝식 바뀌는 차이가 있고 본 글은 마이바티스 스프링 기준으로 작성합니다.
메인 내용은 아니라 접은글로 관리합니다.
레거시 스프링 기준
SessionFactoryBean
Mybatis 설정파일을 바탕으로 SqlSessionFactory를 생성하고 빈 등록이 필요합니다.
- dataSource 주입
- typeAliasPackage, SQL 작성시 필요한 DTO alias 관리
- mapperLocations, SQL 작성한 구현체 XML의 위치 등록
SqlSessionTemplate
SQL 실행이나 트랜잭션 관리를 하는 핵심 클래스이고 SqlSession 인터페이스를 구현하며 Thread-Safe하고 빈 등록이 필요합니다.
- SessionFactoryBean 주입 필요
MapperScannerConfigurer
mapper 인터페이스 스캔후 빈 등록해줍니다.
스프링부트 기준
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.3.1</version>
</dependency>
스프링부트 마이바티스 스타터 의존성 설정하고 Mapper 인터페이스에 @Mapper 어노테이션 붙이면 알아서 인식합니다.
구현체를 별도의 xml로 관리하려면 application 설정파일에서 설정해줘야하지만 SQL 작성을 어노테이션으로 했기에 생략합니다.
1. 스키마 직접 관리
spring:
jpa:
hibernate:
ddl-auto: createJPA를 사용할 땐 Application 설정파일에 이 한줄이면 만들어지던 테이블들을 직접 만들면서 구현하면서 수정이 필요한 부분 덕분에 컬럼을 추가, 삭제, 타입변경을 경험하며 DDL에 대해 익숙해졌습니다.
2. Insert 이후 같은 트랜잭션 내에서 Auto Increment 키 접근
스프링 시큐리티/JWT로 인증, 인가를 관리해서 유저:권한(1:N)의 관계로 관리했습니다.
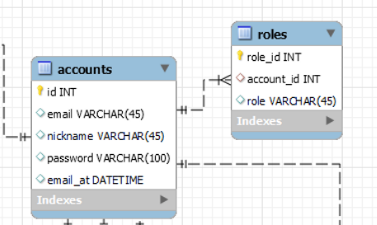
회원가입시에 유저를 insert하고 해당 유저 id를 기준으로 권한 테이블에도 insert가 필요합니다.
JPA
@Entity
public class Account {
@Id
@GeneratedValue
private Long id;
...생략
}JPA는 Auto Increment 엔티티를 관리할 때 persist 시점에 바로 DB로 쿼리를 전송해 PK 값 생성 후 객체에 저장하기에 바로 키에 접근이 가능합니다.
MyBatis
@Mapper
public interface AccountMapper {
@Insert("insert into accounts(email, nickname, password, email_at) values (#{email} , #{nickname} , #{password}, now())")
@Options(useGeneratedKeys = true, keyProperty = "id")
int save(Account account);마이바티스는 @Options을 사용하면 Auto Increment 되는 키에 접근할 수 있습니다.
3. 쿼리압축 & 이유
동일한 결과가 예상되지만 서버에서 많은 쿼리를 발생시키면 네트워크 지연이나 DB 시스템 쿼리 최적화 부담과 같은 성능 이슈가 생길 수 있습니다. 쿼리 압축을 통해 하나의 쿼리가 무거워지면 DB에서 처리하는 시간이 오래걸리지만 압축하지 않은 것과 예상하는 결과는 어차피 같기 때문에 최대한 압축했습니다.
N+1 문제
인증이 성공하면 이후 인가에서 사용하기 위해 JWT 토큰을 만들 때 유저의 간단한 정보와 권한 리스트를 함께 넣어줍니다.
@다양한 어노테이션 생략
public class Account {
private Long id;
private String email;
private String nickname;
private String password;
private LocalDateTime emailAt;
private List<Roles> roles;
}이때는 DB에서 유저 정보를 조회하고, 해당 유저의 권한들을 다시 조회하면 JPA에서 만났던 N+1문제가 발생합니다.
JPA에서는 Fetch Join이나 EntityGraph로 해결할 수 있고, MyBatis는 N+1을 1:1 관계에선 Associate, 1:N 관계에선 Collections로 해결할 수 있습니다.
쿼리 압축
@Mapper
public interface AccountMapper {
@Select("select id, email, password, nickname, email_at from accounts where email = #{email} ")
@Results({
@Result(property = "id", column="id"),
@Result(property = "email", column="email"),
@Result(property = "nickname", column="nickname"),
@Result(property = "emailAt", column="email_at"),
@Result(property = "roles", javaType = List.class, column = "id",
many = @Many(select = "getRoles"))
})
Account findByEmail(String email);
// Collections 사용할 쿼리
@Select("select role_id as roleId, account_id roleAccountId, role from roles where account_id = #{accountId}")
List<Roles> getRoles(@Param("accountId") Long accountId);
}
유저가 권한을 들고 있는 상태로 조회하기 위해 select 문이 여러번 발생되고 아래와 같은 데이터를 매핑해서 반환합니다.
| Account.id | Account 정보.. | Role.id | Role.Account_id | Role |
| 1 | ... | 1 | 1 | ROLE_ADMIN |
| 1 | ... | 2 | 1 | ROLE_USER |
| 1 | ... | 3 | 1 | ROLE_LEAD |
중복되는 유저 정보에 해당하는 Role 정보들은 리스트로 Account.Roles에 담긴채 조회됩니다.
INSERT INTO ~ SELECT

서비스 중에 유저가 특정 팀을 팔로우하고, 팀에 새로운 이벤트가 생기면 팀의 팔로워들에게 알림을 생성하는 로직이 있습니다.
알림 생성 로직은 다음과 같습니다.
1. 팀의 팔로워들을 조회
2. 해당 팔로워들에게 알림 생성
Insert는 항상 insert into values만 사용했어서 1번 쿼리로 조회한 팔로워들을 반복문을 통해 insert를 진행해서 수많은 쿼리를 발생시켰고, 이건 줄여야겠다는 생각을 했습니다.
SELECT의 다중행 결과를 컬럼에 맞게 조작해서 INSERT를 하면 다중행 삽입이 가능하고 팔로워 조회(1)+ 팀의 팔로워수(N)만큼 더 발생하던 쿼리를 하나로 압축할수 있었습니다.
@Mapper
public interface TeamMapper {
@Insert("INSERT INTO notification (account_id, sido_code, keyword, create_at, checked, content_type_id) " +
"SELECT f.account_id, #{sidoCode}, #{keyword}, now(), false, #{contentTypeId} "
+ "FROM follow f JOIN team t ON f.team_id = t.id " +
"WHERE t.id = #{teamId}")
void insertNotification(@Param("teamId")Long teamId, @Param("sidoCode") Integer sidoCode,
@Param("keyword") String keyword, @Param("contentTypeId")Long contentTypeId);
}
동적쿼리
마이바티스는 if, choosen, when, foreach 등을 사용할 수 있는 동적 쿼리를 지원합니다. 전 애플리케이션 단계에서 분기처리를 하고 막상 사용한건 foreach밖에 없지만 쓸모없는 쿼리를 줄이기 위해선 가장 많이 사용하는 것도 foreach 일것같습니다.
위에서 생성된 알림들 중 사용자가 체크박스에 체크하고 읽음처리하거나 전체 읽음처리를 할 때 사용한 쿼리입니다.
@Update("update notification set checked = true"
+ "where id in"
+ "<foreach collections='notifications' item='id' separator=',' open='(' close=')'>"
+ "#{id}"
+ "</foreach>")
void readNotifications(@Param("notifications")List<Notification> notifications);
4. 인라인 뷰(내부쿼리)에서 외부쿼리의 컬럼 접근
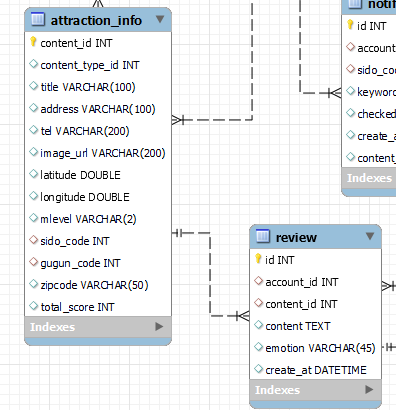
하나의 컨텐츠에 여러개의 리뷰가 달리고, 컨텐츠에서 리뷰 점수의 총합을 관리하고 컨텐츠의 리뷰 개수로 나눠 평균점수를 관리했습니다.
컨텐츠를 하나씩 조회할 때는 평균 점수를 구할 때 문제가 없었지만 평균 점수가 높은 컨텐츠 순서대로 limit를 걸어 사용자에게 추천하려고 할때 당연히 내부쿼리에서 외부 쿼리의 컬럼에 접근이 불가능한줄알고 일단 전체 컨텐츠의 평균점수를 가진 상태로 조회하고 애플리케이션 단계에서 사이즈로 관리를 했었습니다.
구글링을 통해 내부쿼리에서 외부쿼리의 컬럼에 접근이 가능하다는 것을 알고 평균 점수를 구하는 쿼리와 limit를 같은 쿼리내에서 처리했습니다.
@Select("select content_id as contentId, content_type_id as contentTypeId, sido_code as sidoCode, gugun_code as gugunCode,"
+ "title, address, tel, zipcode, image_url as imageUrl, latitude, longitude, mlevel, " // 외부 쿼리 컬럼을 조인 조건으로 걸기
+ "total_score / (select count(*) from attraction_info a join review r on a.content_id = r.content_id where a.content_id = ai.content_id) as avgScore"
+ " from attraction_info ai where ai.sido_code = #{sido} order by avgScore desc limit 3")
List<AttractionResDto> selectBySidoBestScoreLimit3(@Param("sido") Integer sido);후기
프로젝트를 마치고 테이블 생성의 제약조건부터 쿼리를 짜면서 원하는 기능을 구현하기 위한 DB설계 능력은 상승했다고 체감합니다.
왜냐면 테이블과 쿼리를 못짜면 원하는 기능구현이 안되기 때문에... 유저와 권한관리, 관리자와 사용자를 나눠보고, 일대일 대응관계는 하나의 기본키를 두개의 테이블에서 같이 써보고, 쿼리를 압축하기 위해 공부하면서 기초의 중요성을 깨달을 수 있었습니다.