
Index Range Scan

인덱스 루트 블록에서 리프블록까지 수직적으로 탐색한 후 리프 블록을 필요한 범위만 스캔하는 방식
인덱스의 선두컬럼이 조건절에 사용되면 Index Range Scan 활용
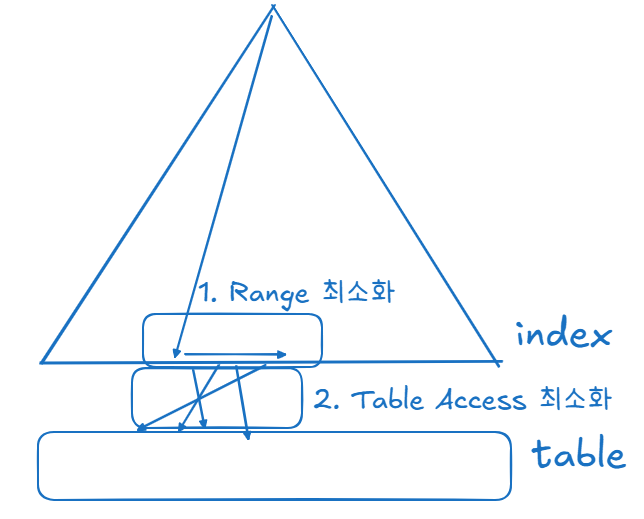
인덱스를 타는 것 자체보다 인덱스 스캔 범위를 최소화하고 인덱스에서 최대한 필터링하고 테이블 액세스를 하는 것이 중요
Index Full Scan

최초의 수직적 탐색 이후 모든 리프블록을 수평적으로 탐색하는 스캔
인덱스의 선두컬럼이 조건절에 없으면 우선적으로 옵티마이저는 Table Full Scan을 고려하지만 대용량 테이블이어서 부담이크다면 인덱스를 활용하는 방법을 고려한다.
데이터 저장공간은 컬럼 길이 * 레코드 수에 의해 결정되므로 인덱스가 차지하는 면적은 테이블보다 훨씬 적다.

테이블 전체를 스캔하기보다 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 일부에 대해서만 테이블 액세스가 발생하도록 할 수 있다면 Table Full Scan보다 Index Full Scan이 유리하다.
또 결과 집합이 인덱스 컬럼 순으로 정렬되므로 Sort Oder by 연산을 생략할 목적으로 사용될 수 있다.

위와 같이 Index에서 필터링 되지 않고 모든 데이터를 다 읽어온다면 모든 테이블의 데이터를 랜덤 액세스로 테이블에 접근하기 때문에 Table Full Scan보다 느릴 가능성이 크다.
하지만 모든 테이블의 데이터에 접근할 때(일반적으로 Table Full Scan이 Index Full Scan보다 유리) 전체 집합 중 처음 일부만을 빠르게 리턴할 목적으로 first_rows 힌트를 활용한다면 옵티마이저는 Table Full Scan이 아닌 Index Full Scan을 활용한다.
이때 결과적으로 처음 일부가 아닌 끝까지 fetch 한다면 Table Full Scan보다 느리므로 first_rows로 인한 Index Full Scan 활용에 주의해야한다.
Index Unique Scan
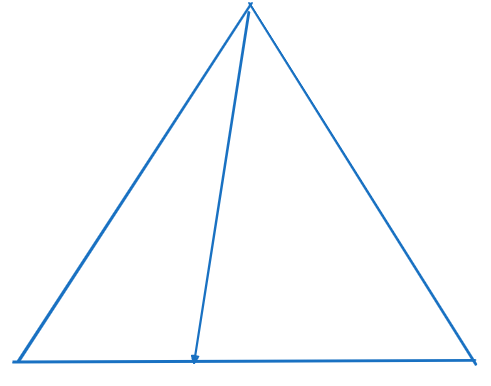
수직적 탐색만으로 데이터를 찾는 스캔 방식
Unique 인덱스를 '=' 조건으로 탐색하는 경우 작동
Unique 인덱스를 범위검색 조건으로 검색하거나, Unique 결합 인덱스에 대해 일부 컬럼으로만 검색할 때 Index Range Scan으로 탐색한다.
Index Skip Scan
인덱스 선두 컬럼이 조건절로 사용되지 않으면 옵티마이저는 기본적으로 Table Full Scan 선택
Table Full Scan보다 I/O를 줄일 수 있거나(인덱스 필터링 多 테이블 액세스 小) 정렬된 결과를 쉽게 얻을 수 있다면 Index Full Scan 활용한다.
Index Skip Scan은 인덱스의 선두 컬럼이 조건절에 빠졌어도 인덱스를 활용하는 방법인데, 조건절에 빠진 인덱스 선두 컬럼의 Distinct Value 개수가 적고(ex 성별) 후행 컬럼의 Distinct Value가 많을 때(ex 사원번호) 유용하다.
Distinct Value가 적은 것은 인덱스로서 분별력이 낮음, 높은 것은 인덱스로서 분별력이 높음
[사원 테이블에서 남자인 사원 찾기 vs 사원 번호가 1111인 사원 찾기]
버퍼 Pinning을 이용한 Skip Scan
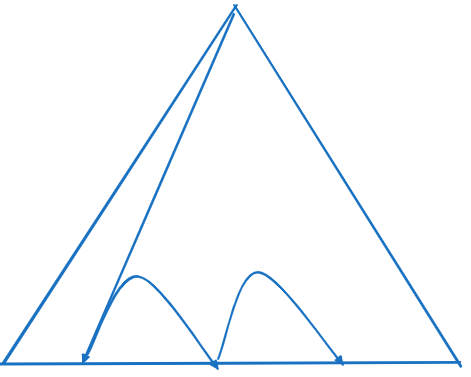
리프 블록은 상위 브랜치나 루트 블록을 가리키는 주소 정보를 갖고 있지 않지만 버퍼 Pinning 기법을 활용해 접근한다.
브랜치 블록 버퍼를 Pinning 한채로 리프 블록에 방문 후 Pinning 한 브랜치 블록으로 되돌아와 다음 방문할 리프 블록을 찾는 과정을 반복한다. 이때 재방문하더라도 Pinning 한 상태이기 때문에 추가적인 블록 I/O는 발생하지 않는다.
인덱스의 최선두 컬럼이 누락되었을 뿐 아니라 결합인덱스에서 중간 컬럼이 조건절에 누락되었을 경우(a+b+c 인덱스에서 b가 누락) 사용할 수 있다.
또 선두컬럼이 부등호, between, like 같은 범위검색 조건일 때도 사용될 수 있다.
In - List Iterator와 비교
select * from emp -- skip scan
where 연봉 betwwen 2000 and 4000
select * from emp -- In-list
where 연봉 betwwen 2000 and 4000
and 성별 in ('남', '여')위와 같이 성별에 대한 조건을 추가해주면 Index Skip Scan에 의존하지 않고 빠른 결과집합을 얻을 수 있지만 In-List 명시하려면 성별 값이 더이상 늘지 않음이 보장되어야 한다. 또 Index Skip Scan과 마찬가지로 조건절에 누락된 인덱스 선두컬럼의 Distinct Value가 적어야하는 것처럼 In-List로 제공하는 값의 종류가 적어야 한다.
하지만 In-List == Index Skip Scan은 아니다.
Index Fast Full Scan
Index Fast Full Scan은 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 MultiBlock Read 방식으로 스캔하기 때문에 Index Full Scan보다 빠르다.
- 결과집합 순서 보장 안됨(인덱스 트리 구조 무시)
- 병렬 스캔 가능
- 인덱스 포함된 컬럼으로만 조회 가능
만약 SQL 내에서 필요한 모든 컬럼(select, where 모두)이 인덱스에 모두 포함되어 있지 않다면 Fast Full Scan 이후 모든 데이터에 대해 rowid로 테이블 액세스가 발생한다.